Protein Data
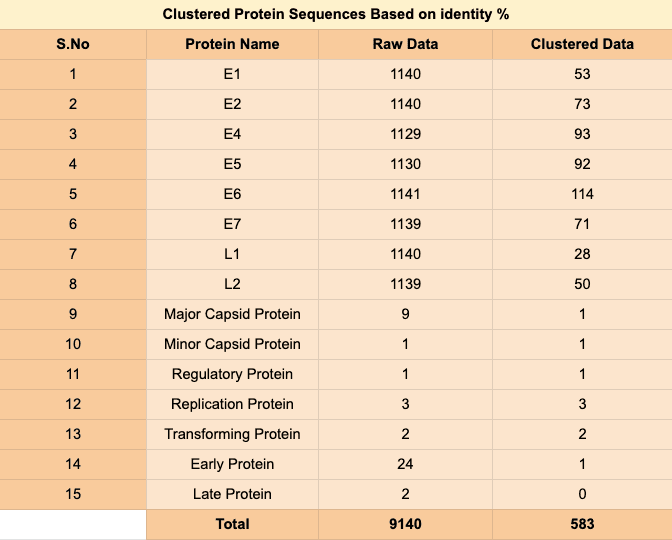
The proteomic sequences of Alphapapillomavirus 9 were extracted from the NCBI Virus and GenBank databases for analysis. A total number of 9140 protein sequences were obtained till October 2021, which were segregated according to their continents. Protein sequences were clustered in order to reduce the number of protein sequences to be analyzed, the clustering was done with the help of tool named CD-Hlt Suite. Clustering was based on identity percentage greater than or equal to 99%, which resulted in 583 unique clusters of protein sequences. The division of unique protein clusters according to the type of protein is depicted in the image below.
click image to interact